























 Colta Specials
Colta SpecialsМежду страхом и ужасом
 © MIT Media Lab
© MIT Media LabНа Восточном побережье США рождается ребенок, и с момента, когда его привозят из роддома домой, за ним (а также за родителями и няней) день и ночь наблюдают 11 камер и 14 микрофонов, вмонтированных в разных углах дома под потолком. За три года накапливается 90 тысяч часов видео и 140 тысяч часов аудиозаписей. Следующие пять лет команда из 70 расшифровщиков — работают от 2 до 15 человек одновременно — тратит только на разбор материалов, относящихся к периоду от девятимесячного до двухлетнего возраста.
Отец ребенка — Деб Рой, профессор Массачусетского технологического института (MIT) и «главный ученый по вопросам медиа» (Chief Media Scientist) в компании Twitter. Его эксперимент над собственным сыном начался 10 лет назад, а сейчас, в сентябре 2015-го, в журнале Proceedings of the National Academy of Sciences напечатана наконец большая академическая статья, подводящая его итоги.
Рой хотел разобраться, откуда берется речь. С подачи Ноама Хомски, классика лингвистики, последние лет сорок принято считать, что в мозгу младенца работает особый «аппарат усвоения языка», который не имеет ничего общего с мучительным и медленным процессом обучения взрослых английскому или китайскому. Этот загадочный «аппарат усвоения» настроен почему-то только на язык. Арифметике, набору простейших действий над числами, семилетнего ребенка приходится учить несколько лет в школе, зато уже трех- или четырехлетний свободно пользуется естественным языком с его зубодробительно сложной системой правил манипуляций знаками (вроде контекстно-свободных грамматик того же Хомского — ваш мозг активно пускает их в ход, даже если сами вы ничего такого не проходили).
Классовые различия не заложены в момент рождения, но дают о себе знать уже к 24-месячному возрасту — и связано это как раз с усвоением языка.
Считается, что младенец слушает разговоры взрослых и впитывает язык как губка. Однако слово «впитывает» создает видимость ясности там, где ясности никакой нет. Достаточно ли усадить младенца на год перед включенным телевизором, где взрослые или герои мультфильмов разговаривают с другими? Если на экране будут одни лекции «Постнауки» и «Арзамаса», произнесет ли он слова «диахрония» и «синхрофазотрон» раньше, чем «мама» и «папа»?
За теоретическим вопросом «как впитывает» может скрываться, например, объяснение, почему из ловушки бедности так трудно выбраться. Равный доступ к образованию не решает проблему: дети из бедных семей хуже учатся (в среднем). Значит ли это, что у них «плохая наследственность», гены тунеядцев и алкоголиков? Вовсе не обязательно. Похоже, классовые различия не заложены в момент рождения, но дают о себе знать уже к 24-месячному возрасту — и связано это как раз с усвоением языка, как показывает эксперимент психологов из Стэнфорда, результаты которого стали известны в 2013 году. Ученых интересовали испаноязычные семьи в США — очевидная группа риска, где бедность часто становится наследственной. Родителей 29 младенцев, которым исполнилось по 19 месяцев, уговорили ненадолго (на срок от дня до шести) положить в карман ребенку диктофон, непрерывно записывающий все звуки вокруг.
В 24 месяца у младенцев сравнили активный словарный запас (с точки зрения когнитивной науки, это не столько про умение говорить, сколько про способность категорно мыслить). Оказалось, что объем словаря у двухлеток прямо зависит не от общего количества слов, которые младенец слышит, а от количества адресованных непосредственно ему. Телевизор или ссоры взрослых друг с другом существенного вклада не вносят.
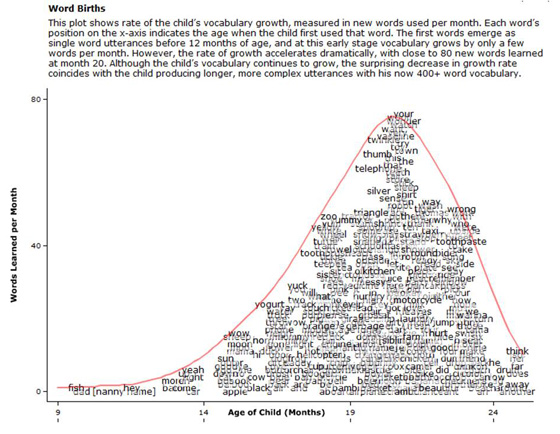 Первые 400 слов младенца© Courtesy of Deb Roy
Первые 400 слов младенца© Courtesy of Deb RoyПри чем здесь бедность? В эксперименте участвовали семьи с доходом ниже 25 тысяч долларов в год (по меркам Калифорнии — крайняя нищета) и до 75 тысяч долларов (что тоже не запредельно много), поэтому ученым было что с чем сравнивать. Бедные часто не могут позволить себе тратить много времени на разговоры с младенцем, оставляют его один на один с телевизором — и предопределяют тем самым разницу в способностях задолго до того, как дело дойдет до учебы.
Но если у психологов из Стэнфорда было всего несколько сотен часов диктофонных записей, то Дебу Рою с его десятками тысяч часов аудио и видео были доступны куда более тонкие детали. К примеру, для каждого из 679 слов, освоенных Роем-младшим к двухлетнему возрасту, был точно вычислен момент, когда оно произносится впервые, — «рождение слова». «The Birth of a Word» — это еще и название лекции TED, прочитанной Роем в 2011 году, когда обработка данных была в разгаре; лекцию с тех пор посмотрели 2 миллиона 100 тысяч раз.
На основе видео Рой строил «словесные ландшафты» — сюрреалистические 3D-рельефы поверх карты дома, где высота соответствует тому, как часто слово произносится в том или ином месте. Например, слову «манго» соответствует острый горный пик на кухне, а какой-нибудь неопределенный артикль равномерно размазан по всему дому. При таком анализе видно, что слова типа «манго», привязанные к тому или иному месту, ребенок усваивает легче, а те, которые произносятся то тут, то там, даются с большим трудом. Самые частые слова, вопреки ожиданиям, ребенок осваивает поздно — потому что это прежде всего местоимения и предлоги, абстрактные по смыслу, и младенец отлично сортирует входящую речь по степени абстракции.
Сравнивая «рождение слова» у младенца с хрониками появления того же слова в речи родителей, можно вычислить, сколько у мозга длится «беременность словом». Или наблюдать, как трансформируются звуки: за полгода «вода» у англоговорящего младенца плавно превращается из «gaga» в «water» (в лекции TED показано, как происходит конкретно это превращение: Рой последовательно вырезал формы одного и того же слова из звукозаписей за шесть месяцев и склеил вместе).
Рой создал компанию медиааналитики Bluefin Labs, которая выясняла, как микроблогеры подхватывают слова из телерекламы. Twitter купил ее за 90 миллионов долларов.
Исследователям пришлось самим изобретать инструменты анализа контента, которые, как оказалось потом, годятся не только для анализа детского лепета. Полуавтоматическая система расшифровки угадывает говорящего — отца, мать, няню или ребенка — по голосу. Сама удаляет интервалы, когда шум есть, а речи нет. А для интерпретации данных в ход пустили и вовсе тяжелую математическую артиллерию: статья перегружена терминами вроде «дивергенция Кульбака—Лейблера» (с ее помощью выясняют, как отклоняются частотные характеристики конкретного слова в речи младенца от характеристик усредненного).
Тот же математический аппарат оказался вполне пригодным для анализа другого сорта лепета, а именно — реакции Твиттера на разные раздражители внешнего мира. Параллельно с экспериментом над сыном Деб Рой создал компанию медиааналитики Bluefin Labs, которая выясняла, как микроблогеры подхватывают слова из телерекламы или как на них влияют сериалы. В 2013 году компанию Роя купил Twitter за 90 миллионов долларов.
Если конкретные методы медиааналитики Bluefin никогда не раскрывались и так и остались коммерческой тайной, то «корпус лепета» — открытые данные, специально подготовленные к тому, чтобы дальше с ними работали другие. Для любопытных авторы статьи создали специальный сайт со статистическими выкладками, а для коллег-исследователей выложили исходники в репозиторий GitHub, где у программистов принято делиться свободно распространяемым кодом. Вряд ли потенциальные пользователи этого кода — одни мамы и папы младенцев, учащихся говорить. У родительской речи, которую «впитывают как губка», в мире информации достаточно аналогов от рекламы до пропаганды, на которых модель как минимум интересно испробовать.
 Поцелуй Санта-Клауса
Поцелуй Санта-Клауса
Запрещенный рождественский хит и другие праздничные песни в специальном тесте и плейлисте COLTA.RU
11 марта 2022
14:52COLTA.RU заблокирована в России
3 марта 2022
14:53Из фонда V-A-C уходит художественный директор Франческо Манакорда
12:33Уволился замдиректора Пушкинского музея
11:29Принято решение о ликвидации «Эха Москвы»
2 марта 2022
18:26«Фабрика» предоставит площадку оставшимся без работы художникам и кураторам
Все новостиColta Specials Colta Specials
Colta Specials Colta Specials
Colta Specials Журналистика: ревизия
Журналистика: ревизия Журналистика: ревизия
Журналистика: ревизияРазговор с основательницей The Bell о журналистике «без выпученных глаз», хронической бедности в профессии и о том, как спасти все независимые медиа разом
29 ноября 2023120751 Журналистика: ревизия
Журналистика: ревизияИзвестный публицист о проигранной борьбе за факт и о конце западноцентричной модели журналистики
17 ноября 2023112979 Журналистика: ревизия
Журналистика: ревизияРазговор с главным редактором независимого медиа «Адвокатская улица». Точнее, два разговора: первый — пока проект, объявленный «иноагентом», работал. И второй — после того, как он не выдержал давления и закрылся
19 октября 202382493 Журналистика: ревизия
Журналистика: ревизияНи с теми, ни с этими. Известный журналист ищет пути между медийными лагерями и обвиняет оппозиционно-эмигрантский в предвзятости
10 октября 2023111979 Colta Specials
Colta Specials Colta Specials
Colta Specials Colta Specials
Colta Specials Colta Specials
Colta Specials