




















 В разлуке
В разлукеРазговор c оставшимся
Мария Карпенко поговорила с человеком, который принципиально остается в России: о том, что это ему дает и каких жертв требует взамен
28 ноября 202492641 Похороны куклы
Похороны куклы
 Краткий курс: свободная музыка
Краткий курс: свободная музыка
 Как реформировать здравоохранение в России?
Как реформировать здравоохранение в России?
 Краткий курс: фри-джаз
Краткий курс: фри-джаз
 Виктор Шендерович. Короткая похвала иронии
Виктор Шендерович. Короткая похвала иронии
 Как написать «Тетрис»
Как написать «Тетрис»
 Как работают поисковые системы
Как работают поисковые системы
 Анатолий Найман: жизнь без рецепта
Анатолий Найман: жизнь без рецепта
 Что такое постсоветский человек?
Что такое постсоветский человек?
 Что такое культура?
Что такое культура?
 Нужен ли госзаказ в кино?
Нужен ли госзаказ в кино?
 С чего начинается музей?
С чего начинается музей?
 © Евгений Дудин / Коммерсантъ
© Евгений Дудин / КоммерсантъВ июле прошлого года не стало Ильи Сегаловича, основателя и директора по технологиям «Яндекса», создателя первой версии поисковика и автора его названия. В память об этом выдающемся человеке и общественном деятеле, который помог многим, в том числе и COLTA.RU, мы републикуем его научно-популярную статью об информационном поиске и математических моделях, которые лежат в его основе. Илья Сегалович называл поисковые системы одним из двух новых чудес света. Во всяком случае, без них и в том числе без главного детища Сегаловича — «Яндекса» наша жизнь была бы совсем другой.
В мире написаны сотни поисковых систем, а если считать функции поиска, реализованные в самых разных программах, то счет надо вести на тысячи. И как бы ни был реализован процесс поиска, на какой бы математической модели он ни основывался, идеи и программы, реализующие поиск, достаточно просты. Хотя эта простота относится, по-видимому, к той категории, про которую говорят «просто, но работает». Так или иначе, но именно поисковые системы стали одним из двух новых чудес света, предоставив homo sapiens неограниченный и мгновенный доступ к информации. Первым чудом, очевидно, можно считать интернет как таковой с его возможностями всеобщей коммуникации.
Существует распространенное убеждение, что каждое новое поколение программ совершеннее предыдущего. Дескать, раньше все было несовершенно, зато теперь повсюду царит чуть ли не искусственный интеллект. Иная крайняя точка зрения состоит в том, что «все новое — это хорошо забытое старое». Думаю, что применительно к поисковым системам истина лежит где-то посередине.
Но что же поменялось в действительности за последние годы? Не алгоритмы и не структуры данных, не математические модели. Хотя и они тоже. Поменялась парадигма использования систем. Проще говоря, к экрану со строчкой поиска подсели домохозяйка, ищущая утюг подешевле, и выпускник вспомогательного интерната в надежде найти работу автомеханика. Кроме появления фактора, невозможного в доинтернетовскую эру, — фактора тотальной востребованности поисковых систем — стала очевидна еще пара изменений. Во-первых, стало ясно, что люди не только «думают словами», но и «ищут словами». В ответе системы они ожидают увидеть слово, набранное в строке запроса. И второе: «человека ищущего» трудно «переучить искать», так же как трудно переучить говорить или писать. Мечты 60—80-х об итеративном уточнении запросов, о понимании естественного языка, о поиске по смыслу, о генерации связного ответа на вопрос с трудом выдерживают сейчас жестокое испытание реальностью.
Как и любая программа, поисковая система оперирует структурами данных и исполняет алгоритм. Разнообразие алгоритмов не очень велико, но оно есть. Не считая квантовых компьютеров, которые обещают нам волшебный прорыв в «алгоритмической сложности» поиска и про которые автору почти ничего не известно, есть четыре класса поисковых алгоритмов. Три алгоритма из четырех требуют «индексирования», предварительной обработки документов, при котором создается вспомогательный файл, сиречь «индекс», призванный упростить и ускорить сам поиск. Это алгоритмы инвертированных файлов, суффиксных деревьев, сигнатур. В вырожденном случае предварительный этап индексирования отсутствует, а поиск происходит при помощи последовательного просмотра документов. Такой поиск называется прямым.
Простейшая его версия знакома многим, и нет программиста, который бы не написал хотя бы раз в своей жизни подобный код:

Несмотря на кажущуюся простоту, последние 30 лет прямой поиск интенсивно развивается. Было выдвинуто немалое число идей, сокращающих время поиска в разы. Эти алгоритмы подробно описаны в разнообразной литературе, есть их сводки и сопоставления. Неплохие обзоры прямых методов поиска можно найти в учебниках, например, Седжвика или Кормена. При этом надо учесть, что новые алгоритмы и их улучшенные варианты появляются постоянно.
Хотя прямой просмотр всех текстов — довольно медленное занятие, не следует думать, что алгоритмы прямого поиска не применяются в интернете. Норвежская поисковая система Fast использовала чип, реализующий логику прямого поиска упрощенных регулярных выражений (fastpmc), и разместила 256 таких чипов на одной плате. Это позволяло Fast обслуживать довольно большое количество запросов в единицу времени.
Кроме того, есть масса программ, комбинирующих индексный поиск для нахождения блока текста с дальнейшим прямым поиском внутри блока. Например, весьма популярный, в том числе и в рунете, Glimpse.
Вообще у прямых алгоритмов есть принципиально беспроигрышные отличительные черты. Например, неограниченные возможности по приближенному и нечеткому поиску. Ведь любое индексирование всегда сопряжено с упрощением и нормализацией терминов, а следовательно, с потерей информации. Прямой же поиск работает непосредственно по оригинальным документам безо всяких искажений.
Эта простейшая структура данных, несмотря на свое загадочное иностранное название, интуитивно знакома как любому грамотному человеку, так и любому программисту баз данных, даже не имевшему дело с полнотекстовым поиском. Первая категория людей знает, что это такое, по «конкордансам» — алфавитно упорядоченным исчерпывающим спискам слов из одного текста или принадлежащих одному автору (например «Конкорданс к стихам А.С. Пушкина», «Словарь-конкорданс публицистики Ф.М. Достоевского»). Вторые имеют дело с той или иной формой инвертированного списка всякий раз, когда строят или используют «индекс БД по ключевому полю».
Проиллюстрируем эту структуру при помощи замечательного русского конкорданса — «Симфонии», выпущенной Московской патриархией по тексту синодального перевода Библии.

Перед нами упорядоченный по алфавиту список слов. Для каждого слова перечислены все «позиции», в которых это слово встретилось. Поисковый алгоритм состоит в отыскании нужного слова и загрузке в память уже развернутого списка позиций.
Чтобы сэкономить на дисковом пространстве и ускорить поиск, обычно прибегают к двум приемам. Во-первых, можно сэкономить на подробности самой позиции. Ведь чем подробнее задана такая позиции (например, в случае с «Симфонией» это «книга+глава+стих»), тем больше места потребуется для хранения инвертированного файла.
В наиподробнейшем варианте в инвертированном файле можно хранить и номер слова, и смещение в байтах от начала текста, и цвет и размер шрифта, да много чего еще. Чаще же просто указывают номер документа (скажем, книгу Библии) и число употреблений этого слова в нем. Именно такая упрощенная структура считается основной в классической теории информационного поиска — Information Retrieval (IR).
Второй (никак не связанный с первым) способ сжатия: упорядочить позиции для каждого слова по возрастанию адресов и для каждой позиции хранить не полный ее адрес, а разницу от предыдущего. Вот как будет выглядеть такой список для нашей странички в предположении, что мы запоминаем позицию вплоть до номера главы:
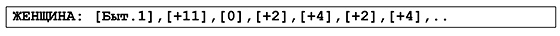
Дополнительно на разностный способ хранения адресов накладывают какой-нибудь простенький способ упаковки: зачем отводить небольшому целому числу фиксированное «огромное» количество байтов, ведь можно отвести ему почти столько байтов, сколько оно заслуживает. Здесь уместно упомянуть коды Голомба или встроенную функцию популярного языка Perl: pack(«w»).
В литературе встречается и более тяжелая артиллерия упаковочных алгоритмов самого широкого спектра: арифметический, Хафман, LZW и т.д. Прогресс в этой области идет непрерывно. На практике в поисковых системах они используются редко: выигрыш невелик, а мощности процессора расходуются неэффективно.
В результате всех описанных ухищрений размер инвертированного файла, как правило, составляет от 7 до 30 процентов от размера исходного текста, в зависимости от подробности адресации.
Неоднократно предлагались другие, отличные от инвертированного и прямого поиска, алгоритмы и структуры данных. Это, прежде всего, суффиксные деревья (Манбер, Гоннет), а также сигнатуры (Фалуцос).
Первый из них функционировал и в интернете, будучи запатентованным алгоритмом поисковой системы OpenText. Мне доводилось встречать суффиксные индексы в отечественных поисковых системах. Второй — метод сигнатур — представляет собой преобразование документа к поблочным таблицам хеш-значений его слов — «сигнатуре» и последовательному просмотру «сигнатур» во время поиска.
Широкого распространения ни тот, ни другой метод не получили, а следовательно, не заслужили и подробного обсуждения в этой небольшой статье.
Приблизительно три из пяти поисковых систем и модулей функционируют безо всяких математических моделей. Точнее сказать, их разработчики не ставят перед собой задачу реализовывать абстрактную модель и/или не подозревают о существовании оной. Принцип здесь прост: лишь бы программа хоть что-нибудь находила. Абы как. А дальше сам пользователь разберется.
Однако, как только речь заходит о повышении качества поиска, о большом объеме информации, о потоке пользовательских запросов, кроме эмпирически проставленных коэффициентов полезным оказывается оперировать каким-нибудь, пусть и несложным, теоретическим аппаратом. Модель поиска — это некоторое упрощение реальности, на основании которого получается формула (сама по себе никому не нужная), позволяющая программе принять решение: какой документ считать найденным и как его ранжировать. После принятия модели коэффициенты часто приобретают физический смысл и становятся понятнее самому разработчику, да и подбирать их становится интереснее.
Все многообразие моделей традиционного информационного поиска (IR) принято делить на три вида: теоретико-множественные (булевская, нечетких множеств, расширенная булевская), алгебраические [1] (векторная, обобщенная векторная, латентно-семантическая, нейросетевая) и вероятностные.
Булевское семейство моделей — по сути, первое, приходящее на ум программисту, реализующему полнотекстовый поиск. Есть слово — документ считается найденным, нет — не найденным. Собственно, классическая булевская модель — это мостик, связывающий теорию информационного поиска с теорией поиска и манипулирования данными.
Критика булевской модели, вполне справедливая, состоит в ее крайней жесткости и непригодности для ранжирования. Поэтому еще в 1957 году Джойс и Нидхэм предложили учитывать частотные характеристики слов, чтобы «... операция сравнения была бы отношением расстояния между векторами...» (Джойс, 1957). Векторная модель и была с успехом реализована в 1968 году отцом- основателем науки об информационном поиске Джерардом Солтоном (Gerard Salton) [2] в поисковой системе SMART (Salton's Magical Automatic Retriever of Text).
Ранжирование в этой модели основано на естественном статистическом наблюдении, что чем больше локальная частота термина в документе (TF) и больше «редкость» (т.е. обратная встречаемость в документах) термина в коллекции (IDF), тем выше вес данного документа по отношению к термину. Обозначение IDF ввела Карен Спарк-Джоунз в 1972 г. в статье про различительную силу (term specificity). С этого момента обозначение TF*IDF широко используется как синоним векторной модели.
Наконец, в 1977 году Робертсон и Спарк-Джоунз обосновали и реализовали вероятностную модель (предложенную еще в 1960-м (Марон)), также положившую начало целому семейству. Релевантность в этой модели рассматривается как вероятность того, что данный документ может оказаться интересным пользователю. При этом подразумевается наличие уже существующего первоначального набора релевантных документов, выбранных пользователем или полученных автоматически при каком-нибудь упрощенном предположении. Вероятность оказаться релевантным для каждого следующего документа рассчитывается на основании соотношения встречаемости терминов в релевантном наборе и в остальной, «нерелевантной» части коллекции. Хотя вероятностные модели обладают некоторым теоретическим преимуществом — ведь они располагают документы в порядке убывания «вероятности оказаться релевантным», — на практике они так и не получили большого распространения.
Я не собираюсь вдаваться в подробности и выписывать громоздкие формулы для каждой модели. Их сводка вместе с обсуждением занимает в сжатом виде 35 страниц в книжке «Современный информационный поиск» (Баэса-Ятес). Важно только заметить, что в каждом из семейств простейшая модель исходит из предположения о взаимонезависимости слов и обладает простым условием фильтрации: документы, не содержащие слова запроса, никогда не бывают найденными. Продвинутые («альтернативные») модели каждого из семейств не считают слова запроса взаимонезависимыми, а кроме того, позволяют находить документы, не содержащие ни одного слова из запроса.
Способность находить и ранжировать документы, не содержащие слов из запроса, часто считают признаком искусственного интеллекта или поиска по смыслу и относят априори к преимуществам модели. Вопрос о том, так это или нет, мы оставим за рамками данной статьи.
Для примера опишу лишь одну, пожалуй, самую популярную модель, работающую по смыслу. В теории информационного поиска данную модель принято называть латентно-семантическим индексированием (иными словами, выявлением скрытых смыслов). Эта алгебраическая модель основана на сингулярном разложении прямоугольной матрицы, ассоциирующей слова с документами. Элементом матрицы является частотная характеристика, отражающая степень связи слова и документа, например, TF*IDF. Вместо исходной миллионноразмерной матрицы авторы метода Фурнас и Дирвестер предложили использовать 50—150 «скрытых смыслов» [3], соответствующих первым главным компонентам ее сингулярного разложения.
Сингулярным разложением действительной матрицы A размеров m*n называется всякое ее разложение вида A = USV, где U — ортогональная матрица размеров m*m, V — ортогональная матрица размеров n*n, S — диагональная матрица размеров m*n, элементы которой sij = 0, если i не равно j, и sii = si >= 0. Величины si называются сингулярными числами матрицы и равны арифметическим значениям квадратных корней из соответствующих собственных значений матрицы AAT. В англоязычной литературе сингулярное разложение принято называть SVD-разложением.
Давным-давно доказано (Экарт), что если оставить в рассмотрении первые k сингулярных чисел (остальные приравнять к нулю), мы получим ближайшую из всех возможных аппроксимацию исходной матрицы ранга k (в некотором смысле ее «ближайшую семантическую интерпретацию ранга k»). Уменьшая ранг, мы отфильтровываем нерелевантные детали; увеличивая, пытаемся отразить все нюансы структуры реальных данных.
Операции поиска или нахождения похожих документов резко упрощаются, так как каждому слову и каждому документу сопоставляется относительно короткий вектор из k смыслов (строки и столбцы соответствующих матриц). Однако по причине малой осмысленности «смыслов» или по какой иной [4], но использование LSI в лоб для поиска так и не получило распространения. Хотя во вспомогательных целях (автоматическая фильтрация, классификация, разделение коллекций, предварительное понижение размерности для других моделей) этот метод, по-видимому, находит применение.
«...проверка устойчивости показала, что перекрытие релевантных документов между любыми двумя асессорами примерно 40% в среднем <...> точность и полнота, измеренная между асессорами, около 65% <...> Это накладывает практическую верхнюю границу на качество поиска в районе 65%...»
(«What we have learned, and not learned, from TREC», Donna Harman)
Какова бы ни была модель, поисковая система нуждается в «тюнинге» — оценке качества поиска и настройке параметров. Оценка качества — идея, фундаментальная для теории поиска. Ибо именно благодаря оценке качества можно говорить о применимости или неприменимости той или иной модели и даже обсуждать их теоретические аспекты.
В частности, одним из естественных ограничений качества поиска служит наблюдение, вынесенное в эпиграф: мнения двух «асессоров» (специалистов, выносящих вердикт о релевантности) в среднем не совпадают друг с другом в очень большой степени! Отсюда вытекает и естественная верхняя граница качества поиска, ведь качество измеряется по итогам сопоставления с мнением асессора.
Обычно [5] для оценки качества поиска меряют два параметра:
1) точность (precision) — доля релевантного материала в ответе поисковой системы;
2) полнота (recall) — доля найденных релевантных документов в общем числе релевантных документов коллекции.
Именно эти параметры использовались и используются на регулярной основе для выбора моделей и их параметров в рамках созданной Американским институтом стандартов (NIST) конференции по оценке систем текстового поиска (TREC — text retrival evaluation conference) [6]. Начавшаяся в 1992 году консорциумом из 25 групп, к 12-му году своего существования конференция накопила значительный материал, на котором до сих пор оттачиваются поисковые системы. К каждой очередной конференции готовится новый материал (т.н. дорожка) по каждому из интересующих направлений. «Дорожка» включает коллекцию документов и запросов. Приведу примеры.
Дорожка произвольных запросов (ad hoc) — присутствует на всех конференциях.
Многоязычный поиск.
Маршрутизация и фильтрации.
Высокоточный поиск (с единственным ответом, выполняемый на время).
Взаимодействие с пользователем.
Естественно-языковая дорожка.
Ответы на «вопросы».
Поиск в «грязных» (только что отсканированных) текстах.
Голосовой поиск.
Поиск в очень большом корпусе (20 GB, 100 GB и т.д.).
WEB-корпус (на последних конференциях он представлен выборкой по домену .gov).
Распределенный поиск и слияние результатов поиска из разных систем.
Как видно из «дорожек» TREC, к самому поиску тесно примыкает ряд задач, либо разделяющих с ним общую идеологию (классификация, маршрутизация, фильтрация, аннотирование), либо являющихся неотъемлемой частью поискового процесса (кластеризация результатов, расширение и сужение запросов, обратная связь, «запросозависимое» аннотирование, поисковый интерфейс и языки запросов). Нет ни одной поисковой системы, которой бы не приходилось решать на практике хотя бы одну из этих задач.
Зачастую наличие того или иного дополнительного свойства является решающим доводом в конкурентной борьбе поисковых систем. Например, краткие аннотации, состоящие из информативных цитат из документа, которыми некоторые поисковые системы сопровождают результаты соей работы, помогают им оставаться на полшага впереди конкурентов.
Обо всех задачах и способах их решения рассказать невозможно. Для примера рассмотрим «расширение запроса», которое обычно производится через привлечение к поиску ассоциированных терминов. Решение этой задачи возможно в двух видах — локальном (динамическом) и глобальном (статическом). Локальные техники опираются на текст запроса и анализируют только документы, найденные по нему. Глобальные же «расширения» могут оперировать тезаурусами, как априорными (лингвистическими), так и построенными автоматически по всей коллекции документов. По общепринятому мнению, глобальные модификации запросов через тезаурусы работают неэффективно, понижая точность поиска. Более успешный глобальный подход основан на построенных вручную статических классификациях, например, веб-директориях. Этот подход широко используется в интернет-поисковиках в операциях сужения или расширения запроса.
Нередко реализация дополнительных возможностей основана на тех же самых или очень похожих принципах и моделях, что и сам поиск. Сравните, например, нейросетевую поисковую модель, в которой используется идея передачи затухающих колебаний от слов к документам и обратно к словам (амплитуда первого колебания — все тот же TF*IDF), с техникой локального расширения запроса. Последняя основана на обратной связи (relevance feedback), в которой берутся наиболее смыслоразличительные (контрастные) слова из документов, принадлежащих верхушке списка найденного.
К сожалению, локальные методы расширения запроса, несмотря на эффектные технические идеи типа Term Vector Database (Стата) и очевидную пользу, все еще остаются крайне «дорогим» [7] удовольствием.
Немного в стороне от статистических моделей и структур данных стоит класс алгоритмов, традиционно относимых к лингвистическим. Точно границы между статистическими и лингвистическими методами провести трудно. Условно можно считать лингвистическими методы, опирающиеся на словари (морфологические, синтаксические, семантические), созданные человеком. Хотя считается доказанным, что для некоторых языков лингвистические алгоритмы не вносят существенного прироста точности и полноты — например, английского (Стржалковски), — все же основная масса языков требует хотя бы минимального уровня лингвистической обработки. Не вдаваясь в подробности, приведу только список задач, решаемых лингвистическими или окололингвистическими приемами:
— автоматическое определение языка документа;
— токенизация (графематический анализ): выделение слов, границ предложений;
— исключение неинформативных слов (стоп-слов);
— лемматизация (нормализация, стемминг): приведение словоизменительных форм к «словарной» (в том числе и для слов, не входящих в словарь системы);
— разделение сложных слов (компаундов) для некоторых языков (например, немецкого);
— дизамбигуация: полное или частичное снятие омонимии;
— выделение именных групп.
Еще реже в исследованиях и на практике можно встретить алгоритмы словообразовательного, синтаксического и даже семантического анализа. При этом под семантическим анализом чаще подразумевают какой-нибудь статистический алгоритм (LSI, нейронные сети), а если толково-комбинаторные или семантические словари и используются, то в крайне узких предметных областях.
«То, что хорошо работает в TREC, часто не срабатывает в вебе <...> некоторые утверждают, что в вебе пользователи обязаны более точно специфицировать то, что им нужно, писать побольше слов в запросах. Мы категорически не согласны с такой точкой зрения. Если люди спрашивают “Билл Клинтон”, они должны получать осмысленные результаты, так как в вебе полным-полно качественной информации на эту тему...»
Сергей Брин, Ларри Пейдж. «The Anatomy of a Large-Scale Hypertextual Web Search Engine»
«...Я был потрясен, когда кто-то из Google сказал мне, что они вообще не используют ничего наработанного в TREC, потому что все алгоритмы, заточенные на дорожке “произвольных запросов”, спам расшибает вдребезги...»
Пора вернуться к теме, с которой началась эта статья: что же изменилось в поисковых системах за последнее время?
Прежде всего, стало очевидно, что поиск в вебе не может быть сколько-нибудь корректно выполнен, будучи основан на анализе (пусть даже сколь угодно глубоком, семантическом и т.п.) одного лишь текста документа. Ведь внетекстовые (off-page) факторы играют не меньшую, а порой и бо́льшую роль, чем текст самой страницы. Положение на сайте, посещаемость, авторитетность источника, частота обновления, цитируемость страницы и ее авторов — все эти факторы невозможно сбрасывать со счета.
Cтав основным источником получения справочной информации для человеческого вида, поисковые системы стали основным источником трафика для интернет-сайтов. Как следствие, они немедленно подверглись «атакам» недобросовестных авторов, желающих любой ценой оказаться в первых страницах результатов поиска. Искусственная генерация входных страниц, насыщенных популярными словами, техника клоакинга, «слепого текста» и многие другие приемы, предназначенные для обмана поисковых систем, мгновенно заполонили интернет.
Кроме проблемы корректного ранжирования создателям поисковых систем в интернете пришлось решать задачу обновления и синхронизации колоссальной по размеру коллекции с гетерогенными форматами, способами доставки, языками, кодировками, массой бессодержательных и дублирующихся текстов. Необходимо поддерживать базу в состоянии максимальной свежести (на самом деле достаточно создавать иллюзию свежести — но это тема отдельного разговора), может быть, учитывать индивидуальные и коллективные предпочтения пользователей. Многие из этих задач никогда прежде не рассматривались в традиционной науке информационного поиска.
Для примера рассмотрим пару таких задач и практических способов их решения в поисковых системах для интернета.
Не все внетекстовые критерии полезны в равной мере. Именно ссылочная популярность и производные от нее оказались решающим фактором, поменявшим в 1999—2000 гг. мир поисковых систем и вернувшим им преданность пользователей. Так как именно с ее помощью поисковые системы научились прилично и самостоятельно (без подпорок из вручную отредактированных результатов) ранжировать ответы на короткие частотные запросы, составляющие значительную часть поискового потока.
Простейшая идея глобального (т.е. статического) учета ссылочной популярности состоит в подсчете числа ссылок, указывающих на страницы. Примерно то, что в традиционном библиотековедении называют индексом цитирования. Этот критерий использовался в поисковых системах еще до 1998 года. Однако он легко подвергается накрутке, кроме того, он не учитывает вес самих источников.
Естественным развитием этой идеи можно считать предложенный Брином и Пейджем в 1998 году алгоритм PageRank — итеративный алгоритм, подобный тому, что используется в задаче определения победителя в шахматном турнире по швейцарской системе. В сочетании с поиском по лексике ссылок, указывающих на страницу (старая, весьма продуктивная идея, которая использовалась в гипертекстовых поисковых системах еще в 80-е годы), эта мера позволила резко повысить качество поиска.
Немного раньше, чем PageRank, был предложен локальный (т.е. динамический, основанный на запросе) алгоритм учета популярности — HITS (Кляйнберг), который [8] не используется на практике в основном из-за вычислительной дороговизны. Примерно по той же причине, что и локальные (т.е. динамические) методы, оперирующие словами.
Оба алгоритма, их формулы, условия сходимости подробно описаны, в том числе и в русскоязычной литературе. Отмечу только, что расчет статической популярности не является самоценной задачей, он используется в многочисленных вспомогательных целях: определение порядка обхода документов, ранжирование поиска по тексту ссылок и т.д. Формулы расчета популярности постоянно улучшают, в них вносят учет дополнительных факторов — тематической близости документов (например, популярная поисковая система www.teoma.com), их структуры и т.п., позволяющих понизить влияние непотизма. Интересной отдельной темой является эффективная реализация соответствующих структур данных (Бхарат).
Хотя размер базы в интернете на поверхностный взгляд не кажется критическим фактором, это не так. Недаром рост посещаемости таких машин, как Google и Fast, хорошо коррелирует именно с ростом их баз. Основная причины: «редкие» запросы, то есть те, по которым находится менее 100 документов, составляют в сумме около 30% от всей массы поисков — весьма значительную часть. Этот факт делает размер базы одним из самых критичных параметров системы.
Однако рост базы кроме технических проблем с дисками и серверами ограничивается и логическими: необходимостью адекватно реагировать на мусор, повторы и т.п. Не могу удержаться, чтобы не описать остроумный алгоритм, применяемый в современных поисковых системах для того, чтобы исключить «очень похожие документы».
Происхождение копий документов в интернете может быть различным. Один и тот же документ на одном и том же сервере может отличаться по техническим причинам: быть представлен в разных кодировках и форматах, содержать переменные вставки — рекламу или текущую дату.
Широкий класс документов в вебе активно копируется и редактируется — ленты новостных агентств, документация и юридические документы, прейскуранты магазинов, ответы на часто задаваемые вопросы и т.д. Популярные типы изменений: корректура, реорганизация, ревизия, реферирование, раскрытие темы и т.д. Наконец, публикации могут быть скопированы с нарушением авторских прав и изменены злонамеренно с целью затруднить их обнаружение.
Кроме того, индексация поисковыми машинами страниц, генерируемых из баз данных, порождает еще один распространенный класс внешне мало отличающихся документов: анкеты, форумы, страницы товаров в электронных магазинах.
Очевидно, что с полными повторами проблем особых нет, достаточно сохранять в индексе контрольную сумму текста и игнорировать все остальные тексты с такой же контрольной суммой. Однако этот метод не работает для выявления хотя бы чуть-чуть измененных документов.
Для решения этой задачи Уди Манбер (автор известной программы приближенного прямого поиска agrep) в 1994 году предложил идею, а Андрей Бродер в 1997-м придумал название и довел до ума алгоритм «шинглов» (от слова shingles — «черепички, чешуйки»). Вот его примерное описание.

Для каждого десятисловия текста рассчитывается контрольная сумма (шингл). Десятисловия идут внахлест, с перекрытием, так, чтобы ни одно не пропало. А затем из всего множества контрольных сумм (очевидно, что их столько же, сколько слов в документе минус 9) отбираются только те, которые делятся на, скажем, 25. Поскольку значения контрольных сумм распределены равномерно, критерий выборки никак не привязан к особенностям текста. Ясно, что повтор даже одного десятисловия — весомый признак дублирования, если же их много, скажем, больше половины, то с определенной (несложно оценить вероятность) уверенностью можно утверждать: копия найдена! Ведь один совпавший шингл в выборке соответствует примерно 25 совпавшим десятисловиям в полном тексте!
Очевидно, что так можно определять процент перекрытия текстов, выявлять все его источники и т.п. Этот изящный алгоритм воплотил давнюю мечту доцентов: отныне мучительный вопрос «у кого студент списывал этот курсовик» можно считать решенным! Легко оценить долю плагиата в любой статье [9].
Чтобы у читателя не создалось впечатление, что информационный поиск — исключительно западная наука, упомяну про альтернативный алгоритм определения почти-дубликатов, придуманный и воплощенный у нас в Яндексе (Ильинский). В нем используется тот факт, что большинство поисковых систем уже обладают индексом в виде инвертированного файла (или инвертированным индексом), и этот факт удобно использовать в процедуре нахождения почти-дубликатов.
Архитектурно современные поисковые системы представляют собой сложные многокомпьютерные комплексы. Начиная с некоторого момента по мере роста системы основная нагрузка ложится вовсе не на робота, а на поиск. Ведь в течение секунды приходят десятки и сотни запросов.
Для того чтобы справиться с этой проблемой, индекс разбивают на части и раскладывают по десяткам, сотням и даже тысячам компьютеров. Сами компьютеры начиная с 1997 года (поисковая система Inktomi) представляют собой обычные 32-битные машины (Linux, Solaris, FreeBSD, Win32) с соответствующими ограничениями по цене и производительности. Исключением из общего правила осталась лишь AltaVista, которая с самого начала использовала относительно «большие» 64-битные компьютеры Alpha.
Поисковые системы для интернета (и вообще все большие поисковые сиcтемы) могут ускорять свою работу при помощи техник эшелонирования и прюнинга.
Первая техника состоит в разделении индекса на заведомо более релевантную и менее релевантную части. Поиск сначала выполняется в первой части, а затем, если ничего не найдено или найдено мало, поисковая система обращается ко второй части индекса. Прюнинг (от англ. pruning — «отсечение, сокращение») состоит в том, чтобы динамически прекращать обработку запроса после накопления достаточного количества релевантной информации. Бывает еще статический прюнинг, когда на основании некоторых допущений индекс сокращается за счет таких документов, которые заведомо никогда не будут найдены.
Отдельная проблема — организовать бесперебойную работу многокомпьютерных комплексов, бесшовное обновление индекса, устойчивость к сбоям и задержкам с ответами отдельных компонент. Для общения между поисковыми серверами и серверами, собирающими отклики и формирующими страницу выдачи, разрабатываются специальные протоколы.
Заметьте, что один процент производительности (скажем, неудачно написанный оператор в каком-нибудь цикле) для десятитысячнокомпьютерной [10] системы стоит примерно ста компьютеров. Поэтому можно себе представить, как вычищается код, отвечающий за поиск и ранжирование результатов, как оптимизируется использование всех возможных ресурсов: каждого байта памяти, каждого обращения к диску.
Решающее значение приобретает продумывание архитектуры всего комплекса с самого начала, так как любые изменения — например, добавление необычного фактора при ранжировании или сложного источника данных — становятся исключительно болезненной и сложной процедурой. Очевидно, системы, стартующие позже, имеют в этой ситуации преимущество. Но инертность пользователей весьма высока: так, например, требуется два-четыре года, чтобы сформированная многомиллионная аудитория сама, пусть и медленно, перешла на непривычную поисковую систему, даже при наличии у нее неоспоримых преимуществ. В условиях жесткой конкуренции это порой неосуществимо.
[1] В отечественной литературе алгебраические модели часто называют линейными.
[2] Gerard Salton (Sahlman), 1927—1995. Он же Селтон, он же Залтон и даже Залман, он же Жерар, Герард, Жерард или даже Джеральд в зависимости от вкуса переводчика и допущенных опечаток.
http://www.cs.cornell.edu/Info/Department/Annual95/Faculty/Salton.html
http://www.informatik.uni-trier.de/~ley/db/indices/a-tree/s/Salton:Gerald.html
http://www.cs.virginia.edu/~clv2m/salton.txt
[3] Для больших коллекций число «смыслов» увеличивают до 300.
[4] После наших экспериментов с LSI получилось, что «смысл номер 1» в рунете — все англоязычные документы, «смысл номер 3» — все форумы и т.п.
[5] Но не обязательно — есть и «альтернативные» метрики!
[6] Материалы конференции публично доступны по адресу trec.nist.gov/pubs.html.
[7] В смысле вычислительных ресурсов.
[8] Точнее, производные от него, так как сам алгоритм оказался не очень устойчив.
[9] В том числе и в данной; надеюсь, что 0%; можете проверить.
[10] Размер кластера Google в конце 2001-го — начале 2002 года.
Modern Information Retrieval
Baeza-Yates R. and Ribeiro-Neto B.
ACM Press Addison Wesley, 1999
The Connectivity Server: Fast Access to Linkage Information on the Web
K. Bharat, A. Broder, M. Henzinger, P. Kumara and S. Venkatasubramanian
WWW7, 1998
The Anatomy of a Large-Scale Hypertextual Web Search Engine
S. Brin and L. Page
WWW7, 1998
Syntactic Clustering of the Web
Andrei Z. Broder, Steven C. Glassman, Mark S. Manasse
WWW6, 1997
Indexing by Latent Semantic Analysis
S. Deerwester, S.T. Dumais, G.W. Furnas, T.K. Landauer, R. Harshman
JASIS, 1990
The Approximation of One Matrix by Another of Lower Rank
Eckart, G. Young Psychometrika, 1936
Description and Performance Analysis of Signature File Methods
Faloutsos, S. Christodoulakis
ACM TOIS, 1987
FAST PMC — The Pattern Matching Chip
http://www.idi.ntnu.no/grupper/KS-grp/microarray/slides/heggebo.pdf
Information Retrieval Using a Singular Value Decomposition Model of Latent Semantic Structure
G.W. Furnas, S. Deerwester, S.T. Dumais, T.K. Landauer, R. A. Harshman, L.A. Streeter and K.E. Lochbaum
ACM SIGIR, 1988
Glimpse, Webglimpse, Unix-Based Search Software…
Examples of PAT Applied to the Oxford English Dictionary
Gonnet G.
University of Waterloo, 1987
What We Have Learned, and Not Learned, from TREC
Donna Harman
The Thesaurus Approach to Information Retrieval
T. Joyce and R.M. Needham
American Documentation, 1958
Authoritative Sources in a Hyperlinked Environment
Jon M. Kleinberg
JACM, 1998
An Efficient Method to Detect Duplicates of Web Documents with the Use of Inverted Index
S. Ilyinsky, M. Kuzmin, A. Melkov, I. Segalovich
WWW2002, 2002
Suffix Arrays: A New Method for On-line String Searches
U. Manber, G. Myers
1st ACM-SIAM Symposium on Discrete Algorithms, 1990
Finding Similar Files in a Large File System
U. Manber
USENIX Conference, 1994
On Relevance, Probabilistic Indexing and Information Retrieval
M.E. Maron and J.L. Kuhns
Journal of the ACM, 1960
Relevance Weighting of Search Terms
S.E. Robertson and K. Sparck Jones
JASIS, 1976
Algorithms in C++
Robert Sedgewick
Addison-Wesley, 1992
A Statistical Interpretation of Term Specificity and Its Application in Retrieval
K. Sparck Jones
Journal of Documentation, 1972
The Term Vector Database: Fast Access to Indexing Terms for Web Pages
R. Stata, K. Bharat, F. Maghoul
WWW9, 2000
Natural Language Information Retrieval
Tomek Strzalkowski (ed.)
Kluwer Academic Publishers, 1999
Алгоритмы: построение и анализ
Т. Кормен, Ч. Лейзерсон, Р. Ривест
МЦНМО, 2000
Симфония, или Словарь-указатель к Священному Писанию Ветхого и Нового Завета
Составители М.А. Бондарев, М.С. Косьян, С.Ю. Косьян
Изд-во Московской патриархии, 1995
Асессор (assessor, эксперт) — специалист в предметной области, выносящий заключение о релевантности документа, найденного поисковой системой.
Булевская модель (boolean, булева, булевая, двоичная) — модель поиска, опирающаяся на операции пересечения, объединения и вычитания множеств.
Векторная модель — модель информационного поиска, рассматривающая документы и запросы как векторы в пространстве слов, а релевантность — как расстояние между ними.
Вероятностная модель — модель информационного поиска, рассматривающая релевантность как вероятность соответствия данного документа запросу на основании вероятностей соответствия слов данного документа идеальному ответу.
Внетекстовые критерии (off-page, внестраничные) — критерии ранжирования документов в поисковых системах, учитывающие факторы, не содержащиеся в тексте самого документа и не извлекаемые оттуда никаким образом.
Входные страницы (doorways, hallways) — страницы, созданные для искусственного повышения ранга в поисковых системах (поискового спама). При попадании на них пользователя перенаправляют на целевую страницу.
Дизамбигуация (tagging, part of speech disambiguation, таггинг) — выбор одного из нескольких омонимов c помощью контекста; в английском языке часто сводится к автоматическому назначению грамматической категории «часть речи».
Дубликаты (duplicates) — разные документы с идентичным, с точки зрения пользователя, содержанием; приблизительные дубликаты (near duplicates, почти-дубликаты), в отличие от точных дубликатов, содержат незначительные отличия.
Иллюзия свежести — эффект кажущейся свежести, достигаемый поисковыми системами в интернете за счет более регулярного обхода тех документов, которые чаще находятся пользователями.
Инвертированный файл (inverted file, инверсный файл, инвертированный индекс, инвертированный список) — индекс поисковой системы, в котором перечислены слова коллекции документов, а для каждого слова перечислены все места, в которых оно встретилось.
Индекс (index, указатель) — см. Индексирование.
Индекс цитирования (citation index) — число упоминаний (цитирований) научной статьи, в традиционной библиографической науке рассчитывается за промежуток времени, например, за год.
Индексирование (indexing, индексация) — процесс составления или приписывания указателя (индекса) — служебной структуры данных, необходимой для последующего поиска.
Информационный поиск (Information Retrieval, IR) — поиск неструктурированной информации, единицей представления которой является документ произвольных форматов. Предметом поиска выступает информационная потребность пользователя, неформально выраженная в поисковом запросе. И критерий поиска, и его результаты не детерминированы. Этими признаками информационный поиск отличается от «поиска данных», который оперирует набором формально заданных предикатов, имеет дело со структурированной информацией и чей результат всегда детерминирован. Теория информационного поиска изучает все составляющие процесса поиска, а именно предварительную обработку текста (индексирование), обработку и исполнение запроса, ранжирование, пользовательский интерфейс и обратную связь.
Клоакинг (cloaking) — техника поискового спама, состоящая в распознании авторами документов робота (индексирующего агента) поисковой системы и генерации для него специального содержания, принципиально отличающегося от содержания, выдаваемого пользователю.
Контрастность термина — см. Различительная сила.
Латентно-семантическое индексирование — запатентованный алгоритм поиска по смыслу, идентичный факторному анализу. Основан на сингулярном разложении матрицы связи слов с документами.
Лемматизация (lemmatization, нормализация) — приведение формы слова к словарному виду, то есть лемме.
Накрутка поисковых систем — см. Спам поисковых систем.
Непотизм — вид спама поисковых систем, установка авторами документов взаимных ссылок с единственной целью поднять свой ранг в результатах поиска.
Обратная встречаемость в документах (inverted document frequency, IDF, обратная частота в документах, обратная документная частота) — показатель поисковой ценности слова (его различительной силы); «обратная» говорят, потому что при вычислении этого показателя в знаменателе дроби обычно стоит число документов, содержащих данное слово.
Обратная связь — отклик пользователей на результат поиска, их суждения о релевантности найденных документов, зафиксированные поисковой системой и использующиеся, например, для итеративной модификации запроса. Следует отличать от псевдообратной связи — техники модификации запроса, в которой несколько первых найденных документов автоматически считаются релевантными.
Омонимия — см. Полисемия.
Основа — часть слова, общая для набора его словообразовательных и словоизменительных (чаще) форм.
Поиск по смыслу — алгоритм информационного поиска, способный находить документы, не содержащие слов запроса.
Поиск похожих документов (similar document search) — задача информационного поиска, в которой в качестве запроса выступает сам документ и необходимо найти документы, максимально напоминающие данный.
Поисковая система (search engine, SE, информационно-поисковая система, ИПС, поисковая машина, машина поиска, «поисковик», «искалка») — программа, предназначенная для поиска информации, обычно текстовых документов.
Поисковое предписание (query, запрос) — обычно строчка текста.
Полисемия (polysemy, многозначность) — наличие нескольких значений у одного и того же слова.
Полнота (recall, охват) — доля релевантного материала, заключенного в ответе поисковой системы, по отношению ко всему релевантному материалу в коллекции.
Почти-дубликаты (near-duplicates, приблизительные дубликаты) — см. Дубликаты.
Прюнинг (pruning) — отсечение заведомо нерелевантных документов при поиске с целью ускорения выполнения запроса.
Прямой поиск — поиск непосредственно по тексту документов, без предварительной обработки (без индексирования).
Псевдообратная связь — см. Обратная связь.
Различительная сила слова (term specificity, term discriminating power, контрастность, различительная сила) — степень ширины или узости слова. Слишком широкие термины в поиске приносят слишком много информации, при этом существенная часть ее бесполезна. Слишком узкие термины помогают найти слишком мало документов, хотя и более точных.
Регулярное выражение (regular expression, pattern, «шаблон», реже «трафарет», «маска») — способ записи поискового предписания, позволяющий определять пожелания к искомому слову, его возможные написания, ошибки и т.д. В широком смысле — язык, позволяющий задавать запросы неограниченной сложности.
Релевантность (relevance, relevancy) — соответствие документа запросу.
Сигнатура (signature, подпись) — множество хеш-значений слов некоторого блока текста. При поиске по методу сигнатур все сигнатуры всех блоков коллекции просматриваются последовательно в поисках совпадений с хеш-значениями слов запроса.
Словоизменение (inflection) — образование формы определенного грамматического значения, обычно обязательного в данном грамматическом контексте, принадлежащей к фиксированному набору форм (парадигме), характерному для слов данного типа. В отличие от словообразования никогда не приводит к смене типа и порождает предсказуемое значение. Словоизменение имен называют склонением (declension), а глаголов — спряжением (conjugation).
Словообразование (derivation) — образование слова или основы из другого слова или основы.
Смыслоразличительный — см. Различительная сила.
Спам поисковых систем (spam, спамдексинг, накрутка поисковых систем) — попытка воздействовать на результат информационного поиска со стороны авторов документов.
Статическая популярность — см. PageRank.
Стемминг — процесс выделения основы слова.
Стоп-слова (stop-words) — те союзы, предлоги и другие частотные слова, которые данная поисковая система исключила из процесса индексирования и поиска для повышения своей производительности и/или точности поиска.
Суффиксные деревья, суффиксные массивы (suffix trees, suffix arrays, PAT-arrays) — индекс, основанный на представлении всех значимых суффиксов текста в структуре данных, известной как «бор» (trie). Суффиксом в этом индексе называют любую «подстроку», начинающуюся с некоторой позиции текста (текст рассматривается как одна непрерывная строка) и продолжающуюся до его конца. В реальных приложениях длина суффиксов ограничена, а индексируются только значимые позиции — например, начала слов. Этот индекс позволяет выполнять более сложные запросы, чем индекс, построенный на инвертированных файлах.
Токенизация (tokenization, lexical analysis, графематический анализ, лексический анализ) — выделение в тексте слов, чисел и иных токенов, в том числе, например, нахождение границ предложений.
Точность (precision) — доля релевантного материала в ответе поисковой системы.
Хеш-значение (hash-value) — значение хеш-функции (hash-function), преобразующей данные произвольной длины (обычно строчку) в число фиксированного порядка.
Частота (слова) в документах (document frequency, встречаемость в документах, документная частота) — число документов в коллекции, содержащих данное слово.
Частота термина (term frequency, TF) — частота употребления слова в документе.
Шингл (shingle) — хеш-значение непрерывной последовательности слов текста фиксированной длины.
PageRank — алгоритм расчета статической (глобальной) популярности страницы в интернете, назван в честь одного из авторов — Лоуренса Пейджа. Соответствует вероятности попадания пользователя на страницу в модели случайного блуждания.
TF*IDF — численная мера соответствия слова и документа в векторной модели; тем больше, чем относительно чаще слово встретилось в документе и относительно реже — в коллекции.
Текст статьи на «Яндексе»
 Поцелуй Санта-Клауса
Поцелуй Санта-Клауса
Запрещенный рождественский хит и другие праздничные песни в специальном тесте и плейлисте COLTA.RU
11 марта 2022
14:52COLTA.RU заблокирована в России
3 марта 2022
14:53Из фонда V-A-C уходит художественный директор Франческо Манакорда
12:33Уволился замдиректора Пушкинского музея
11:29Принято решение о ликвидации «Эха Москвы»
2 марта 2022
18:26«Фабрика» предоставит площадку оставшимся без работы художникам и кураторам
Все новостиВ разлукеМария Карпенко поговорила с человеком, который принципиально остается в России: о том, что это ему дает и каких жертв требует взамен
28 ноября 202492641 В разлуке
В разлукеПроект «В разлуке» начинает серию портретов больших городов, которые стали хабами для новой эмиграции. Первый разговор — о русском Тбилиси с историком и продюсером Дмитрием Споровым
22 ноября 202489444 В разлуке
В разлукеТри дневника почти за три военных года. Все три автора несколько раз пересекали за это время границу РФ, погружаясь и снова выныривая в принципиально разных внутренних и внешних пространствах
14 октября 202490768 В разлуке
В разлукеМария Карпенко поговорила с экономическим журналистом Денисом Касянчуком, человеком, для которого возвращение в Россию из эмиграции больше не обсуждается
20 августа 202494198 В разлуке
В разлукеСоциолог Анна Лемиаль поговорила с поэтом Павлом Арсеньевым о поломках в коммуникации между «уехавшими» и «оставшимися», о кризисе речи и о том, зачем людям нужно слово «релокация»
9 августа 202493929 В разлуке
В разлукеБыть в России? Жить в эмиграции? Журналист Владимир Шведов нашел для себя третий путь
15 июля 202495265 В разлуке
В разлукеКак возник конфликт между «уехавшими» и «оставшимися», на какой основе он стоит и как работают «бурлящие ритуалы» соцсетей. Разговор Дмитрия Безуглова с социологом, приглашенным исследователем Манчестерского университета Алексеем Титковым
6 июля 202495931 В разлуке
В разлукеФилософ, не покидавшая Россию с начала войны, поделилась с редакцией своим дневником за эти годы. На условиях анонимности
18 июня 2024102596 В разлуке
В разлукеПроект Кольты «В разлуке» проводит эксперимент и предлагает публично поговорить друг с другом «уехавшим» и «оставшимся». Первый диалог — кинокритика Антона Долина и сценариста, руководителя «Театра.doc» Александра Родионова
7 июня 2024100617 В разлуке
В разлукеИван Давыдов пишет письмо другу в эмиграции, с которым ждет встречи, хотя на нее не надеется. Начало нового проекта Кольты «В разлуке»
21 мая 202482415 Colta Specials
Colta Specials Colta Specials
Colta Specials